Earlier today Imperial College submitted its annual report on compliance with the Research Council’s open access policy to RCUK. The RCUK OA policy envisages a five year journey after which 100% of RCUK funded scholarly papers should be available as open access in 2018. To support the transition to open access, RCUK have set up a block grant that makes funds available to institutions to cover the cost for article processing charges (APCs) and other OA-related expenses. Funds are awarded in relation to RCUK research funding for institutions, and Imperial College has the second largest allocation, just behind Cambridge and followed by UCL. The annual reports to RCUK give an overview over institutional spend and on compliance.
The headline figures for the 2015/2016 College report are:
£1,051,130 block grant spend from April 2015 to March 2016
89% overall compliance, split in 31% via the gold and 58% via the green route
570 article processing charges paid at an average cost of ~£1,800
The top five publishers are: Elsevier, Wiley, Nature, ACS and OUP
Like every year when discussing the RCUK report figures I think it is important to highlight that compliance rates between universities cannot meaningfully be compared without understanding the data sources and methods used. Just to give one example: the College could also have reported 81% green and 8% gold from the same data.
Why do I caution against directly comparing the numbers? For starters, research-intensive universities find it difficult to establish what 100% is. With hundreds, or in the case of Imperial College many thousand papers published every year we rely on academics to manually notify us for each paper who the funder is. Even though the College has made much progress improving its processes and data over the past few years we have to acknowledge that data collected through such a process will never be complete or fully accurate. For the College report we decided, like in the previous years, to base our analysis on outputs we know to have been RCUK-funded. For this year the size of the sample was 1,923 papers (compared to 1,326 in 2014). With a different sample the numbers would have been different, and other universities may have taken a different approach to analysing the data.
Sadly, it is currently not easy to establish whether an output was made available open access. Publishers do not usually add licensing information to metadata, and searching for manuscripts deposited in external repositories is possible but not necessarily accurate. The process we used for analysis was:
Cross-reference the sample with the journal list from the Directory of Open Access Journals; class every article published in a full OA journal as compliant ‘gold’.
Take the remaining articles and cross-reference with the list of articles for which the College Library has paid an APC; class all those articles as compliant ‘gold’.
Take the remaining articles and cross-reference with the outputs from ResearchFish that show a CC BY license; class all those articles as compliant ‘gold’.
Take the remaining articles and cross-reference with list of outputs deposited in the College repository Spiral; class all those articles as compliant ‘green’.
Take the remaining articles and cross-reference with list of outputs that have a Europe PubMed Central ID; class all those articles as compliant ‘green’.
As in previous years we also put remaining outputs through Cottage Labs Lantern tool but this showed no additional open access outputs. The main reason for that, I suspect, is the high compliance via the green route: some 81% of outputs in the sample had been deposited to the College repository Spiral or to Europe PMC. As the College prefers green over hybrid gold it would have been in line with our policy to report them as green, but as the RCUK prefers gold OA we decided to report all outputs know as gold as such, like in previous years.
I could write more about reporting issues around open access, but as I have done that on a few other occasions I refer those who haven’t suffered enough to my previous posts.
One other caveat should be raised for those planning to analyse the APC spend in comparison with previous years: The APC article level data is based on APCs paid during the reporting period. This differs from the APC data reported in the previous period which was based on APC applications published. There are, therefore, a small number of records duplicated from the previous year. These have been identified in the notes column.
“At a research-intensive university like Imperial it is hard to do anything that doesn’t involve data,” noted Imperial’s Provost when he launched the KPMG Data Observatory last year. The importance of data in research is now commonplace, from proclaiming the rise of a scientific Fourth Paradigm to celebrating “data scientist” as “the sexiest job of the 21st century” and research funders mandating research data management (RDM). Comparatively, software has received less attention – and yet without software there is no data, certainly no “big” data, and no data science either. In fact, there may well be no ‘modern’ research without it – in a 2014 survey 7 out of 10 researchers said it is now impossible to do research without software.
“Better Software Better Research” – SSI, licensed CC BY NC
Despite the importance of research software, academia could improve its support for academic coders. A university career is usually measured on publications, citations, grants and, perhaps, teaching. Focusing on keeping the tools of a research group up-to-date is not likely to give you either, and highly paid industry posts may be more appealing than short term academic contracts.
When I was a student and part-time university staff I was one of the people who developed and maintained digital research infrastructure. At the time, senior colleagues advised us not to risk our careers by becoming ‘mere technicians’ instead of doing ‘real’ research. This attitude has since changed somewhat, but beyond research support roles the career paths for academic software developers are still murky and insecure.
Thankfully, there are now initiatives dedicated to change this. One of them is the UK’s Software Sustainability Institute (SSI), a fantastic organisation with the simple yet powerful slogan: “Better Software, Better Research”. In 2015 I became a fellow of the SSI, and through this blog post I report on some of my related activities.
Supporting Research Software Engineers
Organisations like the SSI help to create a professional identity for coding academics, or research software engineers, as they are now called. One of the recent achievements was the formation of a UK RSE community as a first step to professionalization. Imperial College now has its own RSE group, and I am pleased that I had a chance to contribute a little to its formation. The focus of my fellowship activity was on improving College support for academic software development, and I approached this through policy.
In recent years, UK research funders released a set of policies governing academic research data management. This led to universities defining their own policies and making plans for the corresponding support infrastructure. At the heart of Imperial’s RDM policy is the requirement to preserve the data needed to validate academic publications – reproducibility is a core principle of research, after all. During the policy development I suggested that we should go a step beyond funder requirements to include software. Without code, after all, there is a risk that data cannot be understood. In some cases, the code is arguably more valuable than the data generated by it. This led to our policy requiring that where software is developed as part of a project “the particular version of the software used to generate or analyse the data” has to be archived alongside the data.
One of our principles for policy development was that there would be no College requirement without us providing – directly or indirectly – solutions that enable academics to comply, and that we would seek to add value where possible. This brought up the question: how do you facilitate the archiving, and ideally wider sustainability, of research code?
One answer, in general terms, is: by supporting best practice in software development, in particular the use of version control. Being able to track contributions to code makes it possible to give credit. Being able to distinguish different versions allows researchers to archive the right code. Running a distributed version control system (DVCS) makes it easy to open up the development and share code.
In informal consultation academics pointed to the open source DVCS Git – not surprisingly perhaps, considering its global popularity. We knew from anecdotal evidence that a broad range of DVCS are used at the College. Some academics pay for commercial solutions, others use free web-based options and some groups are hosting their own. There is no central support and coordination, leading to inefficiencies and, to an extent, a lack of central College engagement with academic coders.
Imperial College survey on distributed version control
To better understand current practice, I worked with colleagues in ICT to develop a survey aimed at DVCS users across the College. We launched the survey in November 2015 and circulated it via the RSE community, academic champions and email newsletters. 263 completed responses were received – for what some would call an “esoteric” topic this was a very good response, especially considering that we only approached a fraction of our 4,000 academics directly. The responses also showed that it was not just the usual suspects, such as computer scientists, who have an interest in DVCS (fewer than half of the responses came from the Faculty of Engineering).
Results summary
96% of respondents were aware of Git, and 82% actively use it
The main alternatives to Git are Subversion (65 users), Mercurial (18) and CVS (17)
Of the active Git users:
75% were rating themselves as expert or intermediate
91% use Git for academic research, 22% in teaching and 18% for commercial work
50% use Git for both closed and open development, and about a quarter each use it only or mostly for closed or open development
The main uses of Git are: code/documentation (99%), data/documents (53%), managing configuration files (35%), data sharing/sync (34%), backend for wiki/blog etc. (19%)
GitHub is by far the most popular Git web-repository (79%), followed by Bitbucket (45%) and Gitlab (22%)
Sample survey question: How do you use Git? (check all that apply)
We were particularly interested in finding out whether it would be worthwhile for the College to invest in GitHub, the hosted Git environment. GitHub is free to use, as long as you don’t mind your code being publicly accessible; there is a charge for private code repositories. Some respondents expressed a preference for a College-hosted open source solution or other platforms such as Bitbucket, but many comments pointed to GitHub. Overall there was a consensus that DVCS should be, to quote a participant, “a vital part of e-infrastructure” for an institution like Imperial.
A key requirement that emerged from the consultation was being able to run private code repositories, for example for “codes with commercial or security (e.g. nuclear) related sensitivities”. I am aware that open versus closed can be a controversial topic, but as an organisation with significant industry funding we have to acknowledge that some code cannot be made available publicly. Or, as one respondent put it: “Having a local GitHub Enterprise would definitely add value for us, as we’re working with commercially sensitive data through industrial collaborations, which we can’t put in a publically accessible repository or project management site.”
DVCS like GitHub make it easy for academics to collaborate and share. However, academics value platforms that preserve the integrity of the code while giving them control over what to make publicly accessible and when. The survey pointed to GitHub Enterprise as the preferred platform, a view that was fully endorsed by academics on the College’s RDM steering group.
Following the consultation, the College has made the decision to procure a site licence to GitHub Enterprise. GitHub Enterprise will become a core College service, managed by ICT. There would be no requirement to use GitHub for development, although its use will be encouraged. It was also agreed that we would not simply launch a new out-of-the-box service and hope that that would magically fix all issues. Instead some level of centrally coordinated support and training would be provided – ideally working with groups like the SSI and Software Carpentry. As a first step of the project to launch GitHub Enterprise, focus groups are being set up to gather academic requirements and guide the configuration and introduction of the new service.
Ongoing engagement
Arguably, this does not address concerns about career paths and reward systems for research software engineers. However, it demonstrates that a university like Imperial College values the code written by its staff, and is dedicated to support academic developing of research code. Partly as a result of the consultation, ICT, Library and the Research Office have now increased their engagement with the RSE community. Policy development may not sound like a very exciting task, but where it leads to more communication with and better support for academics I find it worthwhile and exciting enough.
Last week I presented on Imperial’s ORCID implementation at the German Library Congress in Leipzig, as part of a panel on researcher identifiers. The College implemented ORCID in 2014 when it generated identifiers for academic and research staff; see my ORCID article in Insights for details. We use Symplectic Elements, our Current Research Information System (CRIS), to track ORCID iDs and to allow new staff to register – a straightforward process.
However, not all universities have a CRIS and some do not even have an institutional repository (repository systems like DSpace often support ORCID). This has triggered the question, in Leipzig but also in discussions with colleagues in the UK and elsewhere, on how a university should implement ORCID if they do not have a system (or systems budget) for ORCID. Some universities are also not (yet) in a position to become institutional members of ORCID, so they could not integrate with ORCID even if their local systems supported it.
How should a university ‘implement’ ORCID if it has no suitable systems, no or not much of a budget and if it may not be able to become an institutional ORCID member in the immediate future?
This sounds daunting but there is actually a simple, straightforward solution. ORCID is only effective if researchers use their iD – at minimum they should share it with their publisher so the iD can be added to the metadata of their research outputs. Universities can simply encourage staff to self-register – it is free for individuals and only takes a minute. Neither systems support nor ORCID institutional membership are required. Whether to register with ORCID remains the choice of the individual academic, which also gets around lengthy institutional processes for defining policy and evaluating the legal background.
Simply set up a page describing the advantages of ORCID – see Imperial’s ORCID pages as an example-, and start highlighting ORCID as part of the academic engagement that libraries undertake anyway. If and when the university eventually becomes a member of ORCID and makes systems support available you can simply ask researchers to link their existing iD. At that point there may already be some outputs with ORCID in the metadata!
Speaking of systems: I would suggest to add ORCID to a system that gives researchers direct benefit, and to only add it to systems if and when there is a clear business need. For example: if you do not plan to report on ORCID through the HR system, then why implement ORCID there right now?
The key for success with ORCID is to ensure academics understand and use ORCID.
P.S. As part of the support for the UK ORCID consortium, Jisc are currently working on a more detailed decision tree for ORCID implementation, and we are discussing future events to support ORCID uptake.
In what is hopefully not going to become a long series I am today dealing with the joys of compliance reporting in the context of HEFCE’s Policy for open access in the post-2014 Research Excellence Framework (REF). The policy requires that conference papers and journal articles that will be submitted to the next REF – a research assessment through which funding is allocated to UK universities – have to be deposited in a repository within three months of acceptance for publication. Outputs that are published as open access (“gold OA”) are also eligible, and during the first year of the policy the deposit deadline has been extended to three months of publication. The policy comes in force on 1st April and considering the importance of the REF the UK higher education sector is now pondering the question: how compliant are we?
As far as Imperial College is concerned, I can give two answers: ‘100%’ and ‘we don’t know’.
‘100%’ is the correct answer as until 1 April all College outputs remain eligible for the next REF. While correct, the answer is not very helpful when trying to assess the risks of non-compliance and for understanding where to focus communications activities. Therefore we have recently gone through a number crunching exercise to work out how compliant we would be if the policy had been in force since May last year. In May 2015 we made a new workflow available to academics, allowing them to deposit outputs ‘on acceptance’. The same workflow allows academics to apply for article processing charges for open access, should they wish to.
You would imagine that with ten months of data we would be able to give an answer to the question for ‘trial’ compliance, but we cannot, at least not reliably. In order to assess compliance we need to know the type of output, date of acceptance (to work out if the output falls under the policy), the date of deposit and the date of publication (to calculate if the output was deposited within three months). Additionally it would help to know whether the output has been made open access through the publisher (gold/immediate open access).
Below are eight issues that prevent us from calculating compliance:
Publisher data feeds do not provide the date of acceptance
Publishers do not usually include the date of acceptance in their data feeds, therefore we have to rely on authors manually entering the correct date on deposit. Corresponding authors would usually be alerted to acceptance, but co-authors will not always find out about acceptance, or there may be a substantial delay.
Deposit systems do not always require date of acceptance
The issue above is made worse by not all deposit systems requiring academics to enter the date of acceptance. In Symplectic Elements, the system used by Imperial, the date is mandatory only in the ‘on acceptance’ workflow; when authors deposit an output that is already registered in the system as published there is currently no requirement to add the date – resulting in the output listed as non-compliant even if it was deposited in time. Some subject repositories do not even include fields for date of acceptance.
Difficulties with establishing the status of conference proceedings
Policy requirements only apply to conference proceedings with an ISSN. Because of the complexities with the publishing of conference proceedings we often cannot establish whether an output falls under the policy, or at least there is a delay (and possible additional manual effort).
Delays in receiving the date of publication
It takes a while for publication metadata to make it from publishers’ into institutional systems. During this time (weeks, sometimes months) outputs cannot be classed as compliant.
Publisher data feeds do not always provide the date of publication
This may come as a surprise to some, but a significant amount of metadata records do not state the full date of publication. The year is usually included, but metadata records for 18% of 2015 College outputs did not specify year or month. This percentage will be much higher for other universities as the STEM journals (in which most College outputs are published) tend to have better metadata than arts, humanities and social sciences journals.
Publisher data feeds usually do not provide the ‘first online’ date
Technically, even where a full publication date is provided the information may not be sufficient to establish compliance. To get around the problem that publishers define publication dates differently, HEFCE’s policy states that outputs have to be deposited within three months of when the output was first published online. This information is not usually included in our data feeds.
Publisher data feeds do not usually provide licence information
Last year, Library Services at Imperial College processed some 1,000 article processing charges (APCs) for open access. We know that these outputs would meet the policy requirements. However, when the corresponding author is not based at Imperial College – last year around 55% of papers had external co-authors – we have no record on whether they requested that the output be made open access by a publisher. For full open access journals we can work this out by cross-referencing the Directory of Open Access Journals. However, for ‘hybrid’ journals (where open access is an (often expensive) option) we cannot track this as publisher metadata does not usually include licence information.
We cannot reliably track deposits in external repositories
Considering the effort universities across the UK in particular have put into raising awareness of open access there is a chance that outputs co-authored with academics in other institutions have been deposited in their institutional repository. Sadly, we cannot reliably track this due to issues with the metadata. If all authors and repositories used the ORCID identifier it would be easier, but even then institutional repositories would have to track the ORCID iD of all authors involved in a paper, not just those based at their university. If we had DOIs for all outputs in the repositories it would be much easier to identify external deposits.
Considering the issues above, reliably establishing ‘compliance’ is at this stage a largely manual effort that would take too much staff time for an institution that annually publishes some 10,000 articles and conference proceedings – certainly while the policy is not yet in force. Even come April I would rate such an activity as perhaps not the best use of public money. Arguably, publisher metadata should include at least the (correct) date of publication and also the licence, although I cannot see a reason not to include the date of acceptance. If we had that, reporting would be much easier. If we had DOIs for all outputs (delivered close to acceptance) it would be even easier as we could track deposits in external repositories reliably.
Therefore I call on all publishers: if you want to help your authors to meet funder requirements, improve your metadata. This should be in everyone’s interest.
What we can report on with confidence is the number of deposits (excluding theses) to our repository Spiral during 2015: 5,511. Please note: 2015 is the year of deposit, not necessarily year of publication.
In recent years, universities have become more interested in the data researchers produce. This is partly driven by funder mandates, in the UK in particular the EPSRC Expectations, but also by a concern about research integrity as well as an increasing awareness of the value of research data. As a result, universities are building (or procuring) data repositories and catalogues – and these require metadata.
The world is not short of metadata schemas, and yet there is no widely used standard for how research data should be catalogued (not to replace disciplinary schemes, but simply to enable universities to track their assets and others to discover potentially valuable resources). In my keynote at RDMF14 I questioned whether universities building their own data infrastructures is always the most efficient way to address research data challenges, and I suggested that as a minimum we should aim for an agreement on a simple metadata schema for research data. This would save universities the trouble of having to come up with their own metadata fields, and perhaps, more importantly, such a consensus should help us in discussions with platform vendors and other data repositories. Academics are already using a wide range of disciplinary resources as well as generic repositories, and if we want to be able to harvest, search and exchange data we need a core metadata schema. This would also reduce the burden on academics to have to re-enter metadata manually.
One of the colleagues interested in this idea was Marta Teperek from Cambridge. After RDMF we exchanged the metadata fields currently used for research data at Imperial and Cambridge, with the idea to start a wider discussion. Today Marta and myself attended the kick-off meeting of Jisc’s Research Data Shared Service Pilot where we learned that Jisc are working on a schema for metadata – and there is considerable overlap, also with other initiatives. It seems the time is ripe for a wider discussion, and perhaps even for a consensus on a what could be the minimalist core of metadata fields or research data. Minimalist, to make it easy for researchers to engage; core, to allow institutions to extend it to meet their specific requirements.
To facilitate that discussion, I am going to propose a Birds of a Feather session at next week’s International Digital Curation Conference on this topic. As a starting point I have put together a suggestion, inspired by the fields used in the data catalogues at Imperial and Cambridge:
• Title
• Author/contributor name(s)
• Author/contributor ORCID iD(s)
• Abstract
• Keywords
• Licence (e.g. CC BY)
• Identifier (ideally DOI)
• Publication date
• Version
• Institution(s) (of the authors/contributors)
• Funder(s) (ideally with grant references; can also be “none/not externally funded”)
I would be interested to hear your thoughts – in person at IDCC or another event, or in the comments below. I will update this post with feedback from IDCC.
Update, 23/03/2016: Having discussed this with colleagues at IDCC I thought it useful to clarify something. As I mentioned above there are already several metadata schemas out there, and as you will see from the fields I have proposed above this is not about introducing something new. The issue that we face is that systems either don’t include such fields or they are not mandatory. I would like to explore if we can find a consensus on what is considered the mandatory minimum for discovery and funder compliance (including reporting). For example, institutions need to know who funded an output, but a widely used schema designed for a different purpose may list funder as optional. So in that sense this is not about a new schema as such, but about agreeing what has to be implemented as mandatory in order for us to link systems, reduce duplication etc. That could result in a new schema, but doesn’t have to.
Update, 26/03/2016: Back from IDCC; we had an interesting and wide-ranging discussion. Perhaps not surprisingly, we spent most of the time agreeing on definitions and understanding the use case. Most of the participants of the session were not from the UK and therefore not familiar with UK funder requirements.UK institutions are essentially looking for a pragmatic solution that helps us track datasets, report and meet funder requirements for discoverability. Introducing the concept of discoverability may not have been helpful for the international discussion as it made the proposal sound bigger than it is. We have no plans to replace or supersede disciplinary schemas (where these exist); the aim simply is to be able to point to disciplinary or other external repositories so that someone looking at data from an institutional system can learn that there is a dataset, what it may be about and where to locate it – and, ideally, further information such as detailed disciplinary metadata.
From the discussions with this international audience I am mostly drawing two conclusions: 1) This may be, at least partly, a UK-specific issue. 2) When engaging in discussions with metadata experts there is no such thing as a pragmatic definition – speaking about funder compliance and internal track of datasets for reporting is the more useful question.
Despite claims to the contrary, open access as such is not very complicated. Either publish your scholarly output with a publisher who will immediately make it available as open access, or put a copy of the (peer-reviewed) manuscript in a repository. What makes open access complicated is the myriad of policies that regulate it.
The Registry of Open Access Repository Mandates and Policies (ROARMAP) alone lists way over 700 OA policies – just from research organisations and funders. If you add publisher policies it gets even more confusing. As a sector we often complain about the difficulties publishers create with journal embargoes. We are also criticising funders for not aligning their policies. These criticisms are valid, but we tend to gloss over that universities are not always aligning their policies either. Policies that vary across universities make it more difficult for third parties to provide solutions as they need to map onto a wide range of workflows resulting partly from different policies. Different institutional policies also make it harder to communicate open access to academics.
I have on a few occasions suggested that we should aim to align institutional policies more, and that we should also simplify them. Thankfully, I am not the only one thinking about this. Jisc, SHERPA Services and ROARMAP have jointly developed a Schema for Open Access policies. The schema should help policymakers “to express their policies in a systematic manner”, as “an initial step to ensure greater clarity and uniformity in the way information about OA policies is recorded and made available”. Imperial College was one of 30 institutions that provided information to the new initiative. You can read more about the schema, initial findings and how to engage on the Jisc blog.
My ideal would be that over time we move to a single open access policy, or at least to a core policy to which institutions can add a selection of clearly defined elements to reflect their specific needs – where this is really necessary, of course. In the UK we do already have what could be considered the core of an OA policy, the Policy for open access in the post-2014 Research Excellence Framework. Leaving the details aside, the policy requires deposit on acceptance (for publication). Currently it only applies to scholarly articles and conference proceedings, but I would argue that that makes it ideal as a starting point as these more formalised outputs (compared to e.g. performances) are easier to deal with across institutions.
Therefore, my suggestion for a minimal universal OA policy would be:
Publish in the journal of your choice, including full open access journals (subject to availability of funding).
Deposit a copy of the peer reviewed manuscript of your journal article or conference proceeding into a repository on acceptance for publication.
Incidentally, that is effectively the OA policy at Imperial College. As the vast majority of College publications are articles or conference proceedings we can effectively limit the policy to these, at least for the moment. An institution with a more diverse range of outputs may decide to add monographs, videos, websites etc., and those who cover costs for hybrid open access (Imperial’s own fund does not support it) may want this included as well.
I fully understand that just two bullet points will not be enough. However, I would like to put out a challenge: look at your institution’s open access policy and think about which elements you really need, and how you could simplify it in a way that would help us moving towards a universal policy. And make sure to check out the schema!
Earlier today Imperial College London submitted its open access compliance report to RCUK. Like most UK universities, the College is in receipt of an annual open access block grant from RCUK. The funds are made available to support universities in meeting the requirements of the RCUK open access policy, in particular meeting the cost of article processing charges (APC) to make articles open access through the publisher. RCUK allocate funds in relation to research effort and Imperial College receives the second largest grant – £1,353,480 for 2014/15 (Cambridge is #1 with £1,355,073). The report, based on a template developed by Jisc, details how the money has been spent and provides headline compliance figures. It has been put together by the College Library and the Research Office, with support from ICT.
The headline figure is an estimated 31% compliance via the gold and 38% compliance via the green route; we also provide details on APCs for 350 open access articles processed by the College Library. However, before you delve further into the spreadsheet or start comparing these figures to other universities I would like to draw your attention to some of the inherent issues with these reports and figures.
First of all you may notice that the numbers do not seem to add up. We report an APC spend of £597,029 and yet the 350 APCs add up to £679,721.08. The reason for this apparent mismatch is that the first figure is for the period from April 2014 to March 2015, as requested in the spreadsheet, whereas the APCs are reported to RCUK until August 2015.
Secondly, the number of APCs does not equal 31% of the outputs we report on. This is because some of the articles originating from RCUK funding have been paid for by other institutions, usually because the principal investigator was based there and not at Imperial College.
Most importantly though I would caution against directly comparing compliance figures between universities – unless you know exactly how they have been calculated. The biggest challenge, especially for large research intensive universities, is establishing what 100% is: how many outputs are related to RCUK funding? Currently there is no reliable way to derive funder information from article metadata, even where authors report the funders to the publisher. RCUK-funded authors are asked to report outputs to the research councils, but the reporting period does not overlap with the OA reporting period. That means even if all authors would reliable link all outputs to all relevant grants (this is a manual process) the information would not be sufficient to report on. Earlier this year Imperial College introduced a new workflow (for depositing outputs on acceptance) that encourages authors to link outputs and funding, but it will be a while until we can be reasonably confident that close enough to 100% of outputs are linked to all relevant grants.
Why do we not just manually go through all articles and speak to the authors? It is a question of scale – College academics publish between 10,000-12,000 articles and conference proceedings per year. We estimate that some 4,000 of these outputs may be linked to RCUK funding.
So how did we come to the compliance figures reported to RCUK? We analysed a sample of some 1,500 outputs we know to be linked to RCUK funding. Sadly, there is currently no reliable way to automatically establish the open access status of an output as publishers do not usually add licence information to output metadata and tracking outputs in repositories also creates problems. We do of course know how many outputs the College Library paid an APC for and also which outputs were deposited into the College repository Spiral. We do not know where other universities have paid an APC for an article, or where an author may have used departmental or other funds to pay an APC.
We were able to identify additional open access outputs by cross-referencing our data with the list from the Directory of Open Access Journals (DOAJ) and the Europe PubMed Central database. Even so we will have missed outputs, for example papers deposited into repositories like arXiv. We do track arXiv deposits, but there is currently no way of telling what version has been deposited. Even if we knew the version, deposits in repositories pose another problem: where an APC has been paid and the output deposited, do we report it as green or gold OA? In the case of RCUK we have decided to mark it as gold, as that is the preferred route for the UK research councils, but others may have decided differently.
I could go on much longer, but I hope the above gives you an idea of the issues that universities face when reporting on open access. Should you still want to compare university open access reports, make sure to check the data source and methods. The good news is that in the future these reports should become more meaningful, in particular when publishers and system vendors add funder, institutional and author identifiers (such as ORCID) to output metadata.
Finally, I would like to highlight two issues we raised with RCUK when submitting the report:
Many points made by the College in last year’s submission regarding policy implementation are still valid (see paragraphs 35 ff.). The College has made good progress in delivering support infrastructure (significantly reducing processing time for gold and green OA), but concerns about the wider policy landscape and publisher support for open access remain. In particular, we would like to highlight two points:
Hybrid open access remains significantly more expensive than full OA (~50% more per APC), even without taking into account “double dipping”. Processing APCs for hybrid journals continues to require more resource, i.e. in relation to licensing and invoicing. The Finch report saw hybrid as a means of transitioning from a subscription to a full OA model, but there is very little evidence of that transition taking place. The majority of OA funds are still spent on hybrid.
Differences in funder policies make it harder for academics to understand how to comply and increase the workload for support services. RCUK is encouraged to harmonise policy requirements with other funders, in particular with the Policy for open access in the post-2014 Research Excellence Framework. We note that HEFCE have made changes to align policies with regards to gold OA and we would encourage RCUK to consider a similar step for green OA.
On Monday 28th September representatives of over 50 UK universities, ORCID, Jisc, GuildHE, RCUK and CRIS vendors met at Imperial College London for the first UK ORCID members meeting, and to launch the Jisc ORCID consortium. ORCID provides a persistent identifier that links researchers to their professional activities and outputs – throughout their career, even if they change name or employer. The unique iD ensures that authors receive credit for their work and allows institutions to automate information exchange with other organisations such as funders, thereby increasing data quality, saving academics time and institutions money.
In 2014, Imperial College London was one of the first universities in the UK to make ORCID available to researchers, working with the Jisc-ARMA-ORCID pilot. We have since actively engaged with ORCID and the community to increase uptake and improve systems integration.The UK ORCID meeting was designed to bring together different strands of these discussions, andto facilitate a broad discussion about the next steps for ORCID in the UK. Following the pilot programme, Jisc has negotiated an ORCID consortium through which universities can benefit from premium ORCID membership at significantly reduced cost. The meeting was the official launch event for the consortium.Over the last two years ORCID, a relatively new initiative, has gained a lot of momentum, not just in the UK:
over 1.65m researchers registered globally
ORCID iDs associated with over 4.3m DOIs
over 300 member organisations
3 national consortia agreements signed (Italy, UK and Denmark) with more in progress
In 2011, Jisc had set up a “researcher identifier” task and finish group, that included funders, libraries, IT directors, research managers and organisations like HESA. This group eventually recommended ORCID as a solution for the UK. Since then, ORCID has seen increasing support from research organisations and funders. Recently, both the Wellcome Trust and NIHR have mandated the use of ORCID for grant applications. RCUK’s Overview of Systems Interoperability Project resulted in a strong endorsement for ORCID, as did HEFCE’s Report of the Independent Review of the Role of Metrics in Research Assessment and Management.
The UK ORCID meeting was not in the first instance about funders and their mandates though, it was about a discussion between the ORCID member organisations, the Jisc consortium and the way we as a community want to move forward. Specifically, the meeting had four aims:
to raise awareness and understanding of ORCID and the Jisc consortium offer and benefits
to bring together the UK ORCID community and establish how we want to work together
to discuss community expectations for system and platform providers, funders and publishers
to inform the Jisc technical and community support offering
The aim of the morning session was to raise awareness and create a shared understanding of ORCID. It started with presentations from ORCID and Jisc, followed by four university case studies from the pilot programme (Kent, Imperial, Oxford and York) and a Q&A panel. After lunch we discussed community requirements, and ways to work together to achieve these. Four thematic areas were discussed in breakout groups, organised through a community document where participants and others who could not attend in person, had listed their issues and expectations in advance of the meeting. This approach helped focus the discussions and led to a broad agreement on key issues.
Below is my summary of the key community requirements:
CRIS and repository platforms:
actively prompt users to link their ORCID iD
facilitate iD creation by pre-populating ORCID profiles with institutional affiliation and other relevant information
harvest metadata for outputs associated with an iD from other systems
allow users to push output metadata into the ORCID registry
Publishers:
collect ORCID iDs for all authors, not just the corresponding author
make iDs of all authors available with output metadata
mint DOIs on acceptance and link to authors’ iDs
make the author accepted manuscript available on acceptance, with an ID
Funders:
fully integrate ORCID into their workflows and systems
move towards mandating ORCID
This is only a high-level summary of a much richer discussion. Some of the detail that I have conveniently skipped over will no doubt lead to further discussions later, but I found it remarkable how broad the consensus was – across more than 50 universities with very different approaches, requirements and cultures. There is still a lot of work to be done until we can reap all of the benefits that ORCID can enable, but the members meeting showed that universities are keen to work together with Jisc and ORCID to make progress.
Universities across the UK are now actively considering how to roll out ORCID, and there was much interest in lessons learned and emerging best practice. A UK ORCID mailing list is currently being set up and Jisc and ORCID are looking into ways to capture and share information through the new consortium. Jisc are currently hiring for staff to support the consortium and help members to implement ORCID. I am looking forward to follow-on discussions with Jisc, ORCID and the community about the next steps.
When you come at it for the first time, open access looks pretty complicated. Funder policies, institutional policies, publisher policies, different flavours of OA including ‘green’, ‘gold’, ‘libre’ and ‘gratis’ and a whole new language with mystifying terms like ‘hybrid journal’, ‘article processing charge’ and ‘author accepted manuscript’ await. Even librarians sometimes struggle to understand journal policies, or what certain licensing conditions actually mean.
It was perhaps for this reason that, when we started the College open access project, academics gave us a clear mission: a one button solution to open access.
We haven’t quite achieved that yet, but since May we are running a new workflow that reduces the complexity to one sentence: ‘When you have a paper accepted, deposit the peer-reviewed manuscript – we do the rest, no matter what type of open access.’
The workflow is based on two ideas:
Ask authors for the minimum information required.
Offer authors a single publications workflow that covers green and gold OA as well information required for funder reporting.
The frontend for this workflow is Symplectic Elements, the system used by our academics to manage their scholarly outputs. We have worked with the vendor to deliver an OA workflow that kicks in on acceptance for publication, and then we customised the system to interface with ASK OA, our in-house APC management system.
On acceptance for publication, authors add minimal metadata and the manuscript to Elements, link the article to relevant grants and if they want the College to pay an open access charge they simply tick a box. Colleagues in the Library’s open access team then check the submission, set necessary embargoes and make the output available through Spiral, the College repository. If payment is requested, the data is automatically transferred to ASK OA, the cloud-based, workflow-driven system that we launched last year. Through that process, authors receive a purchase order number to send to their publisher. When the College receives the electronic invoice, our finance system matches the PO and the payment process starts. No author interaction needed.
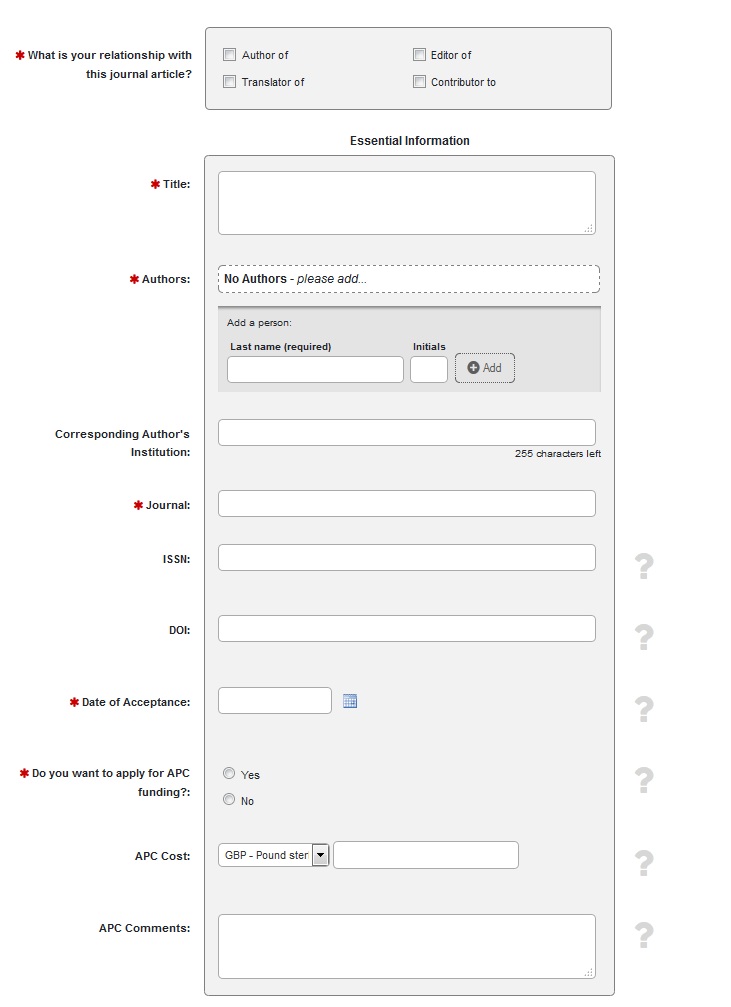
Above you see a screenshot of the information we require from authors. In addition, they deposit the manuscript (or share a link if it was already deposited in an external repository) and link the output to relevant grants. That allows us to charge costs for open access publishing to the correct funders and, once funder systems are ready, will enable the College to automate funder reporting on research outputs. If you want to see a demonstration, check out this video guide produced by the College Library:
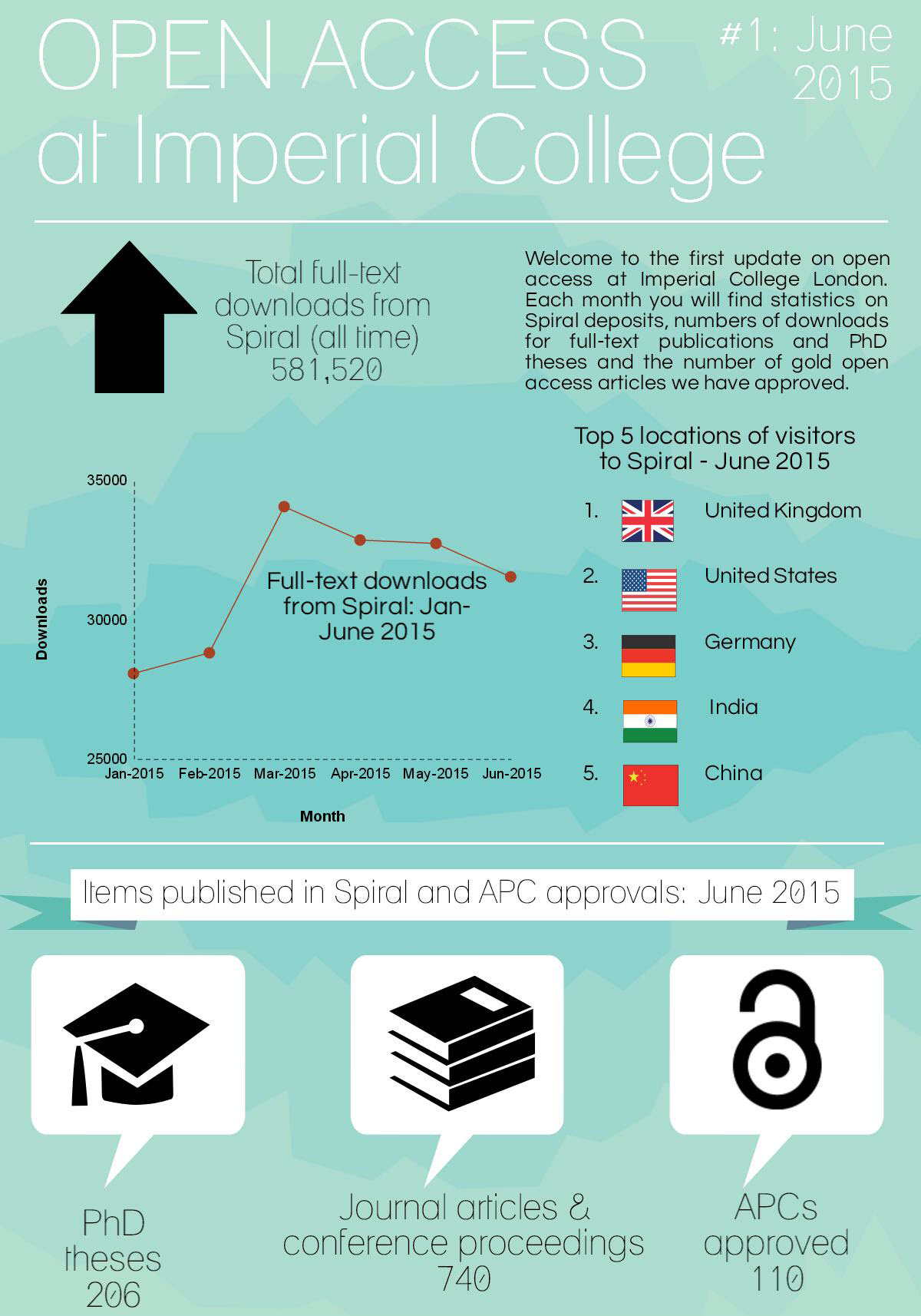
The feedback we had from academics has been positive so far, and the numbers show that as well:
While the workflow is working well so far, we are still far away from what I would consider the ideal scenario. There are still enough journals with difficult and unhelpful policies, and no university workflow will be able to fix that. Publishers being unable to issue correct invoices is another issue. We also have the problem to reliably match the metadata entered on acceptance with the metadata for the published output. Publishers could help by issuing authors with a DOI on acceptance.
Even better, publishers could feed publication metadata into systems like CrossRef on the date of acceptance. If the metadata had funder, licence and embargo information attached and a link to the manuscript, then open access would indeed become a one-click-problem. Authors enter their data on submission, and following acceptance it automatically travels through all relevant systems, until it ends up in an institutional repository. There would be no additional effort for authors, and admin overhead would be reduced greatly. The components to enable this already exist, for example the author identifier ORCID that was rolled out across the College last year.
We are still working towards the goal of a “one button” solution for open access with our partners. Until then the message remains: deposit the manuscript on acceptance, we do the rest.
Just in time before the College closes for the Christmas break I have found the time to write my overdue summary of recent developments in the world of open access and scholarly communication. Below are a few of the headlines and developments that caught my eye during the last couple of months.
Cost of Open Access
Commissioned by London Higher and SPARC Europe, Research Consulting have published Counting the Costs of Open Access. Using data provided by universities, including Imperial College, it concludes that there was a £9.2m cost to UK research organisations for achieving compliance with RCUK’s open access policy in 2013/14. Main conclusions are quoted below – the estimated costs for meeting REF open access requirements are particularly interesting seeing as HEFCE do not provide any funding for their in some ways even more ambitious open access policy:
The time devoted to OA compliance is equivalent to 110 fulltime staff members across the UK.
The cost of meeting the deposit requirements for a post-2014 REF is estimated at £4-5m per annum.
Gold OA takes 2 hours per article, at a cost of £81.
Green OA takes just over 45 minutes, at a cost of £33.
Pinfield, Salter and Bath published: The ‘total cost of publication’ in a hybrid open-access environment. The study analyses data from 23 UK institutions, including Imperial College, covering the period 2007 to 2014. It finds that while the mean value of APCs has been relatively stable, ‘hybrid’ subscription/OA journals were consistently more expensive than fully-OA journals. Modelling shows that APCs are now constituting 10% of the total cost of ownership for publishing (excluding administrative costs).
EBSCO’s 2015 Serials Price Projection Report assumes price increase of 5-7%, not including a recommended additional 2-4% to allow for currency fluctuations.
John Ulmschneider, Librarian at the Virginia Commonwealth University, estimates that with current price increases the cost for subscription payments would “eat up the entire budget for this entire university in 20 years”. Partly in response to that, VCU has launched its own open access publishing platform.
UK Funder News
Arthritis Research UK, Breast Cancer Campaign, the British Heart Foundation (BHF), Cancer Research UK, Leukaemia & Lymphoma Research, and the Wellcome Trust have joined together to create the Charity Open Access Fund (COAF). COAF operates in essentially the same way as the WT fund it replaces.
A new Danish open access strategy sets the goal to reach Open Access to 80% of all publically funded peer-reviewed articles in 2017, concluding with 100% in 2022.
The Open Access policy of the Austrian FWF requires CC BY (if Gold OA) and deposit in a sustainable repository on publication. The FWF covers APCs up to a limit of €2500.
Research Information published a summary of international developments around open access: The Research Council of Norway is making funding available to cover up to 50% of OA publishing charges. The Chinese Academy of Sciences and the National Natural Science Foundation of China require deposit of papers in an OA repository within 12 months of publication. The Mexican president has signed an act to provide “Mexicans with free access to scientific and academic production, which has been partially or fully financed by public funds”.
The launch of Science Advances, a journal of the American Association for the Advancement of Science (AAAS), prompted strong criticism of the AAAS approach to open access. Over a hundred scientists signed an open letter criticising AAAS for charging $1000 for the CC BY license as well as $1500 for papers longer than ten pages – on top of a $3000 base APC. This has been picked up by media including the New Statesman.
The Nature Publishing Group has had two major OA-related headlines. Generally well received was the announcement that NPG would switch the prestigious Nature Communications to full open access. On the other hand, the move to give, limited, read access to articles has been widely criticised as beggar access and a step back for open access: NPG allow those with a subscription to give others viewing (not printing) access to papers, through a proprietary software.
An open letter signed by nearly 60 open access advocates, publishers, library organisations and civil society bodies warns against model licenses governing copyright on open access articles proposed by the International Association of Scientific, Technical & Medical Publishers (STM). The letter says the STM licences “would limit the use, reuse and exploitation of research” and would “make it difficult, confusing or impossible to combine these research outputs with other public resources”. The STM licenses are seen as incompatible with Creative Commons licences.
Jisc and Wiley have negotiated a deal that provides credits for article processing charges (APCs) to universities that license Wiley journal content and have a Wiley OA account.