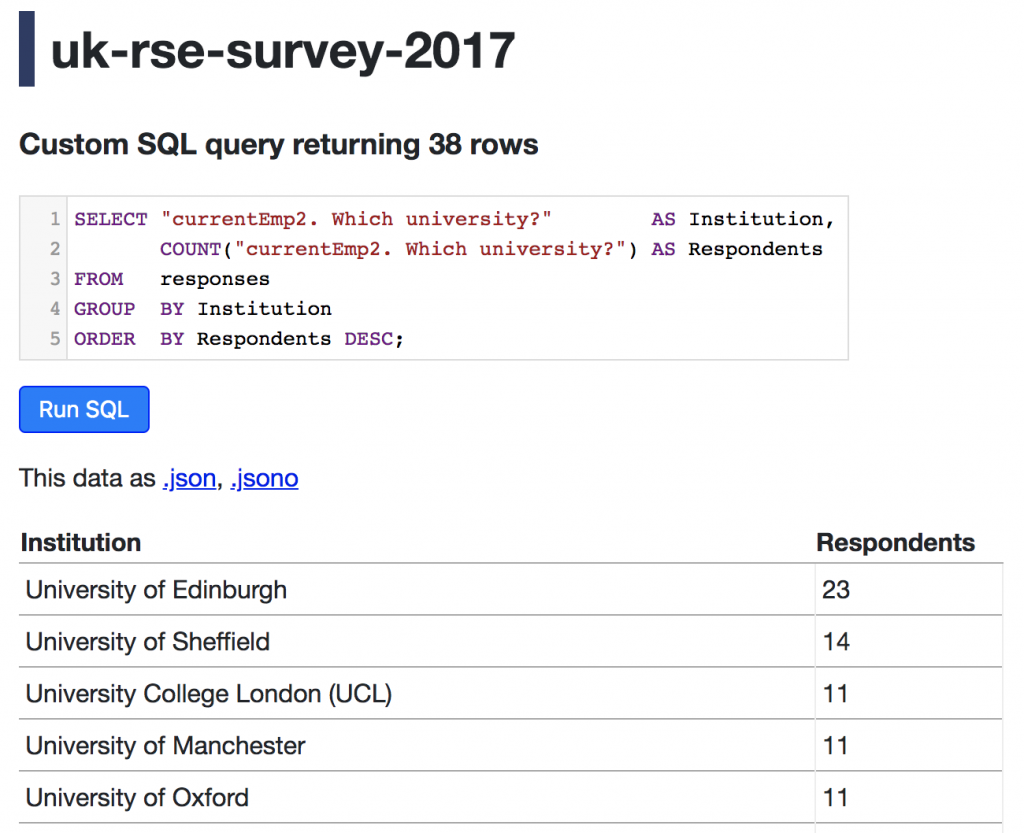
Using the Cloud for Research Software Engineering
We previously described three RSE-related use cases for Microsoft’s Azure platform, ranging in deployment granularity from VMs to individual JavaScript functions. In this post we’ll explain further how we use those and other Azure services to complement our on-premise infrastructure – helping us to deliver our RSE projects faster.
At Imperial we’re fortunate to have a powerful and well-maintained high-performance computing (HPC) system. We use this as a batch processing back-end for user-facing web applications that we have developed (such as Smart Forming) and for benchmarking projects including MUSE. The web applications themselves are typically hosted on CentOS VMware virtual machines hosted in our data centre and maintained by a dedicated team within ICT. These servers are set up to authenticate against our institutional sign-on system, are pre-configured with monitoring and alerting, and can directly access other on-premise systems (such as the HPC cluster and our Research Data Store).
Despite this local infrastructure we still derive a lot of value from access to our institutional Azure subscription, in both ad hoc and longer-term use of cloud resources. This gives us capabilities that would be difficult or costly to replicate on-premise. These include:
- The ability to rapidly provision and tear-down systems and services
- Access to higher-level (lower-maintenance) abstractions i.e. PaaS and FaaS
- Access to a diverse range of operating systems and configurations, from VMs for multiple versions of Windows to macOS build agents
In particular we rely on the following services:
- DevOps Pipelines: Cross-platform QA (primarily testing and linting) and packaging (including PyInstaller builds on macOS and Windows). Build failures are pushed to relevant Teams channels.
- Functions: Our Trending app provides us with information about active repositories in our institutional GitHub organisation. Using Functions makes its deployment zero-maintenance.
- App Service: Our GtR app provides us with alerts for new UKRI grants to Imperial College. It is deployed to App Service to avoid the setup and maintenance required of a standalone VM.
- Cosmos DB: Both GtR and Trending use the MongoDB API provided by Cosmos.
- Virtual Machines: We use Azure when we need VMs for long-running services that are required to accept incoming requests from other systems but don’t need access to on-premise resources, or when we need short-lived VMs for testing purposes:
- We use a Container Linux VM to run Fathom, which aggregates usage stats for some of our externally accessible apps (POWBAL, our Research Software Community Newsletters, and our Research Software Directory)
- We use Windows 7 and Windows 10 VMs to manually test relevant projects in the environments matching those of the intended end-users
- We use CentOS VMs to test in-development versions of applications, including those developed in collaboration with the Cardiovascular Genetics & Genomics Group at Imperial (CardioClassifier and VariantFX)
- Container Registry: We use continuous deployment for all our web apps (including MAGDA and POWBAL), meaning that pushing to the master branch in GitHub is sufficient to run our QA pipeline, build a Docker image which is pushed to the Azure registry, and for Watchtower to pull the image onto the target server and restart the relevant service(s).
- Single Sign-On: This allows users of our internal apps to authenticate using their existing Office 365 accounts – avoiding the need for further login details.
- Notebooks: We have our own Jupyter server attached to our cluster and data store, but Azure Notebooks are very useful for sharing externally, and for teaching large classes.
In short, Azure provides us with services that work alongside our existing systems, enabling us to deliver RSE projects more effectively and with much lower operational overheads than if we tried to replicate the same features on-premise. And by becoming familiar with these services we’re better equipped to advise and assist researchers across Imperial College who wish to take advantage of all the compute resources at their disposal – on-premise and in the cloud.





 In this post we’ll demonstrate how to run deploy a simple scheduled task: a
In this post we’ll demonstrate how to run deploy a simple scheduled task: a