ResearchGate vs. institutional repositories: Which one should I use?
Academic social network sites are currently used by researchers to share their research as well as collaborate with others studying in a similar field. Sites such as ResearchGate and Academia.edu and Mendeley are popular too. However, this does not necessarily make them the right place to share research. In this blog post, we explain why researchers at Imperial College London should use academic social network sites in addition to, not instead of, institutional repositories (such as Spiral). You will also find out about important differences between the two.

Why should I use an institutional repository?
Institutional repositories are officially recognised by governments, publishers, and funders for depositing published research – whereas academic social network sites are not. Even if a publisher does permit uploading a paper to ResearchGate, this will not ensure compliance with the UK’s REF 2021, research funders like the Wellcome Trust or future cOALition S (Plan S) OA requirements. This is because these policies clearly state that scholarly outputs are to be made available through institutional (or open access) repositories. Therefore, unlike academic social network sites, depositing your paper in one (such as Spiral) makes you compliant with funders, publishers and future ones too!
Copyright matters
If you upload a paper to one of these platforms, the risk of copyright infringement is a lot higher. That’s because many of these sites have no mechanism to check for publishers’ copyright permissions and policies. A recent study showed that “201 (51.3%) out of 392 non-OA articles [deposited in ResearchGate] infringed the copyright and were non-compliant with publishers.” The majority of infringement, the study highlights, occurred because the wrong version was deposited. There have also been around 7 million take-down notices for unauthorised content on ResearchGate given by various 17 different publishers which indicates how serious the issue is.
Institutional repositories, on the other hand, are managed (usually by a library team such as the Imperial Open Access Team) and they always check which version they are allowed to upload to a repository as open access. So, if you mistakenly sent the wrong version of an article, one of them will notify you and ask for a different version. They will also ensure the various embargo policies of publishers for you. Therefore, the risk of copyright infringement is very low when using a repository.
We’re hassle-free
Academic social network sites are commercial companies. This fact creates significant drawbacks. For example, some publishers only permit depositing papers in not-for-profit repositories, which means that ResearchGate and its equivalents cannot be used at all to deposit any version of the file. They also make a profit from your research outputs by selling data, advertising jobs or providing a premium service. For this reason, their services may discontinue, shut down or change to preserve profits. In such a case, the papers you have already uploaded to these platforms may no longer be available. Being commercially-run brings another hassle too: A subscription is necessary to upload a paper to these sites or even for reaching the content of a paper. This means they keep your personal data, or worse, may use it in a direct (by email notifications) or indirect (by selling data) way.
We’re here to stay
As institutional repositories are non-profit platforms, none of the disadvantages mentioned above will occur. Institutional repositories, such as Spiral, serve as a permanent archive for collecting, preserving, and disseminating the intellectual output of an institution. Did we say permanent? We are not going anywhere. Therefore, research outputs deposited in institutional repositories will be preserved and freely accessible to the public for a long time, similar to public archives. Additionally, users can immediately access and download the contents of research outputs from the repositories without a subscription or log-in. And in fact if something is closed access, end users can Request a Copy (under the Fair Dealing exception in UK copyright law) – see an example. We never ask or use your personal data.
Love your repository
In short, there are many reasons to use institutional repositories and to be careful about using academic social network sites. We advise that Imperial researchers always deposit their papers first in Spiral which will provide you with a permanent resolvable link (such as http://hdl.handle.net/10044/1/73113) that you can safely post anywhere including ResearchGate. By depositing your paper in Spiral, you will ensure compliance with funders and publishers. So, you should use ResearchGate in addition to Spiral not instead of it. If you still want to deposit to academic social network sites, you can do it the legal way and check what publishers permit via the website SHERPA RoMEO. Lastly, repositories are trusted permanent archives for an institution’s research – they respect copyright law as well as promote open access to research – please use them!
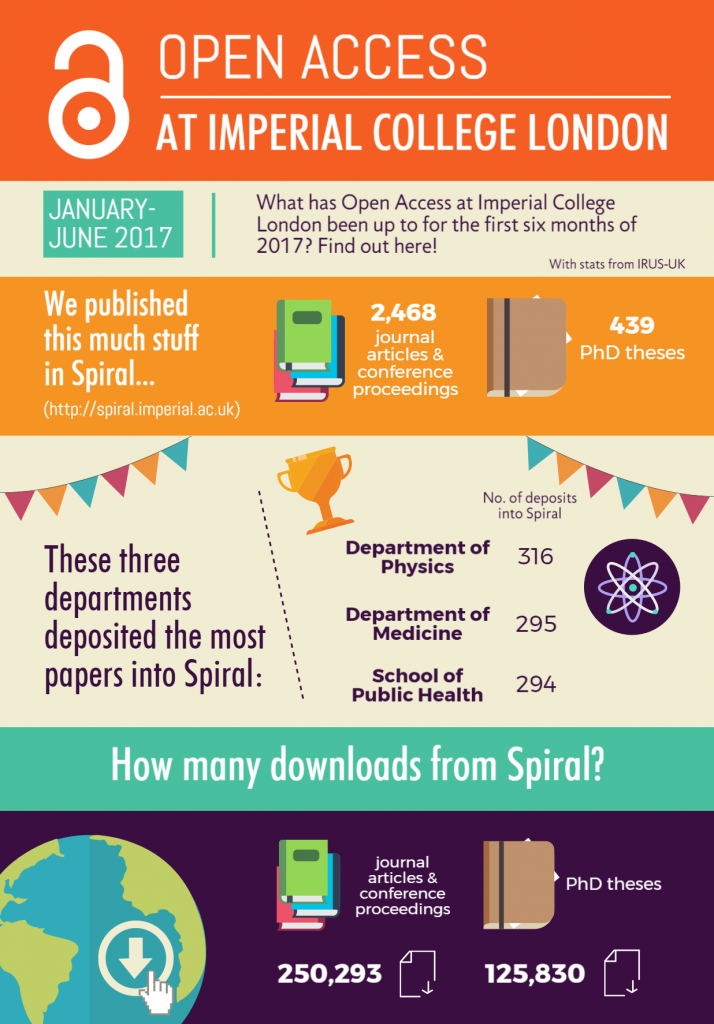
Please don’t forget to check out our leaflet below which covers the same topic in a more visual way. You can also download it via Spiral (http://hdl.handle.net/10044/1/74076).
*This blog post used some arguments of the article authored by Katie Frtney and Justin Gonder (from the University of California). The article is licensed under Creative Commons Attribution 4.0 International (CC BY 4.0). Find the original article at https://osc.universityofcalifornia.edu/2015/12/a-social-networking-site-is-not-an-open-access-repository/
* Another article written by Kathleen Fitzpatrick is also worth reading. Find the article at https://kfitz.info/academia-not-edu/
[infogram id=”54d20ab6-510d-4e99-829c-e2a291c15619″ prefix=”xaR” format=”interactive” title=”Copy: ResearchGate_leafletV2.pdf”]