Blog posts
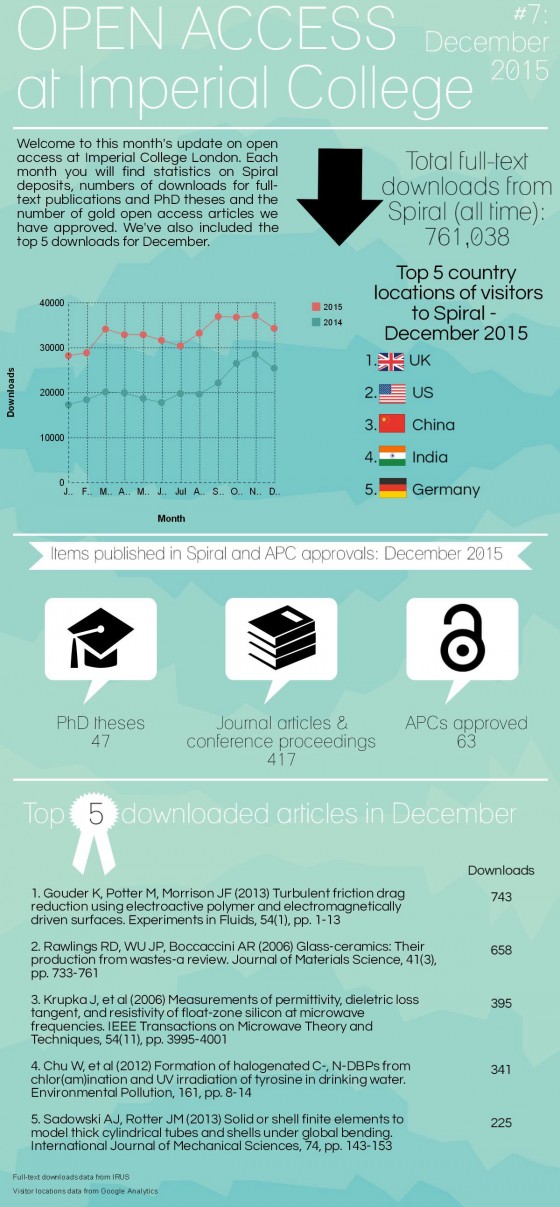
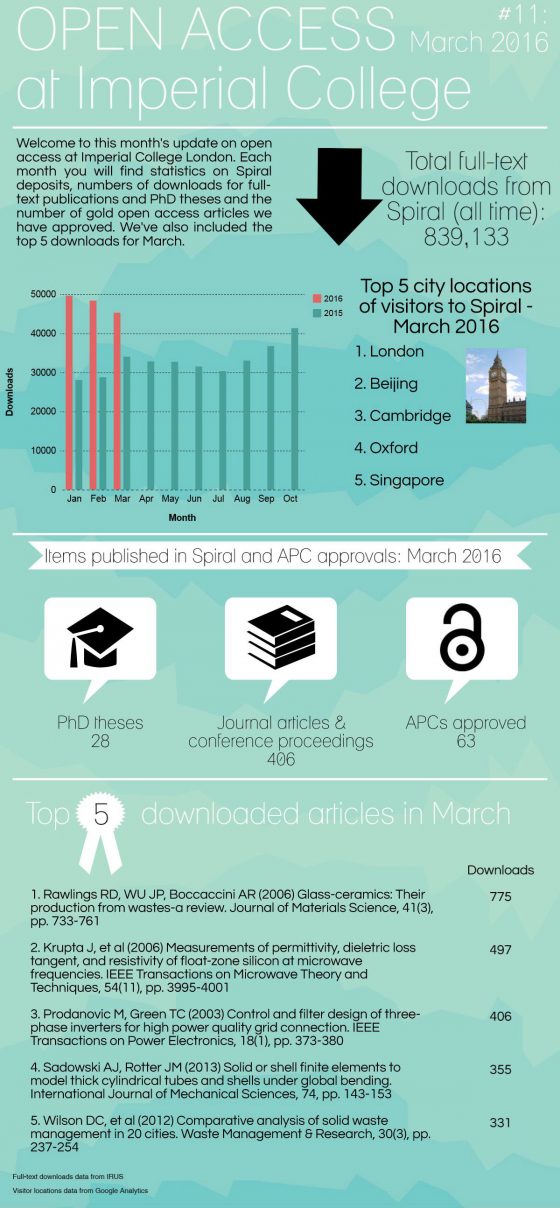
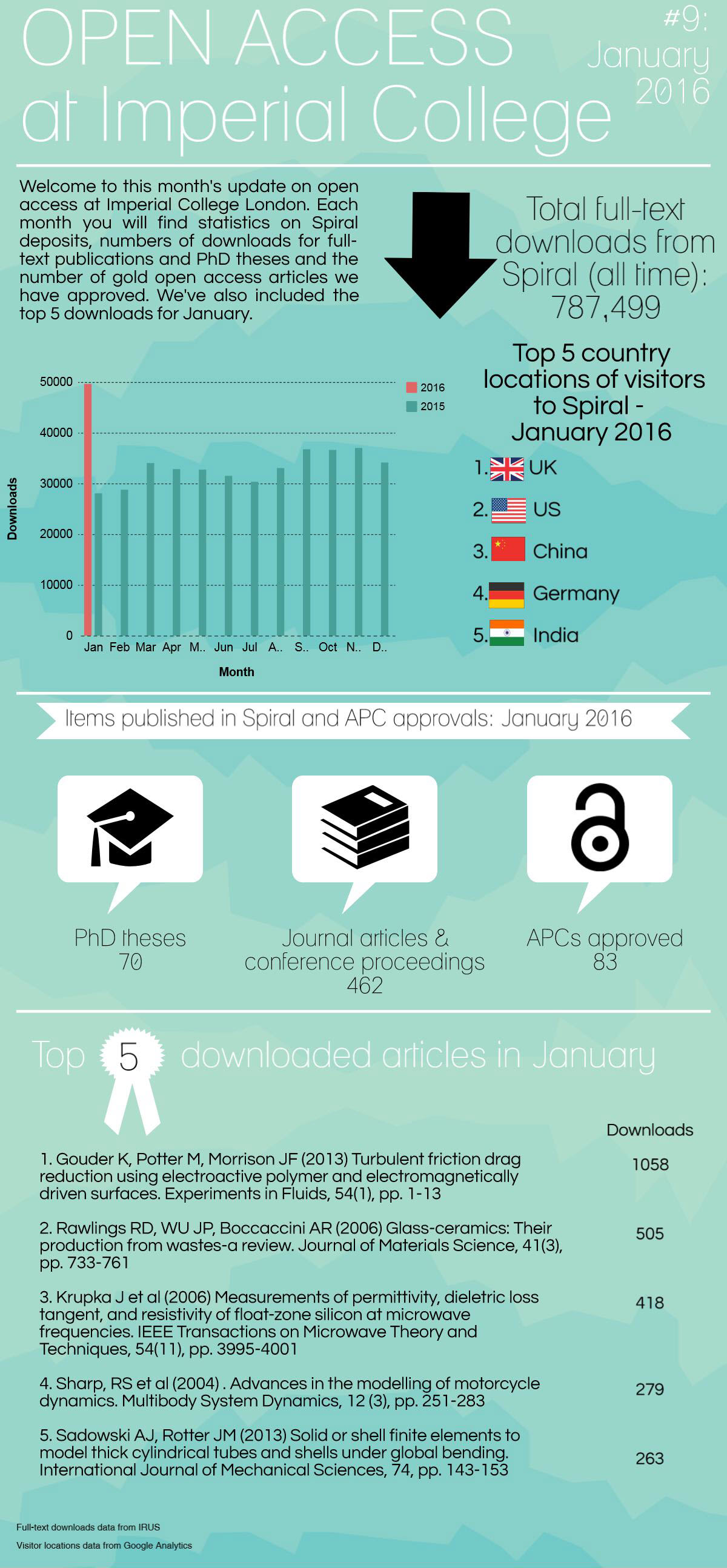
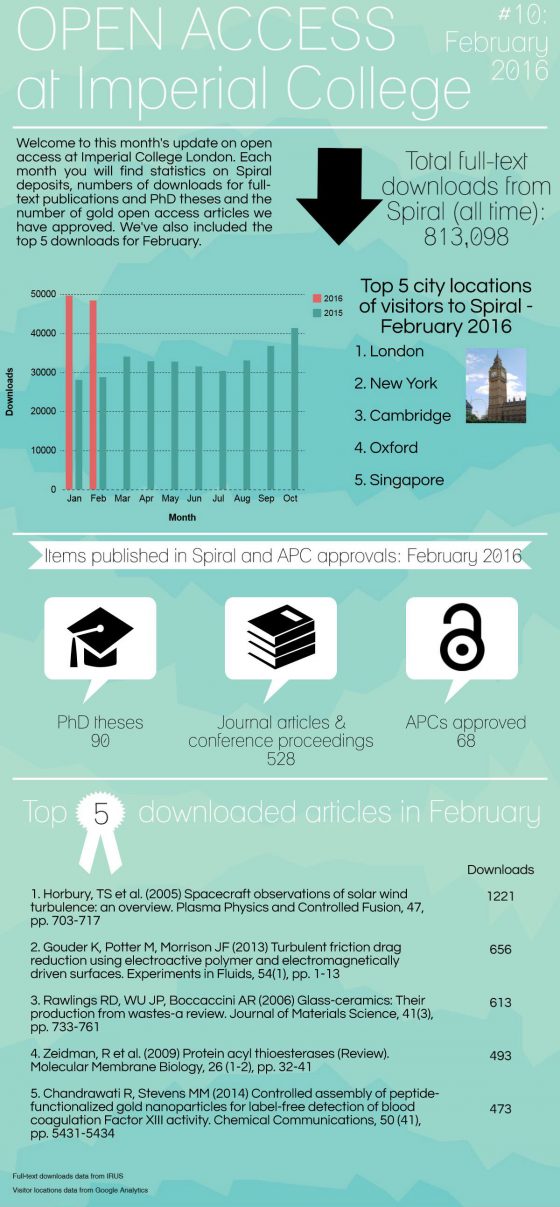
Open access in numbers – April 2016
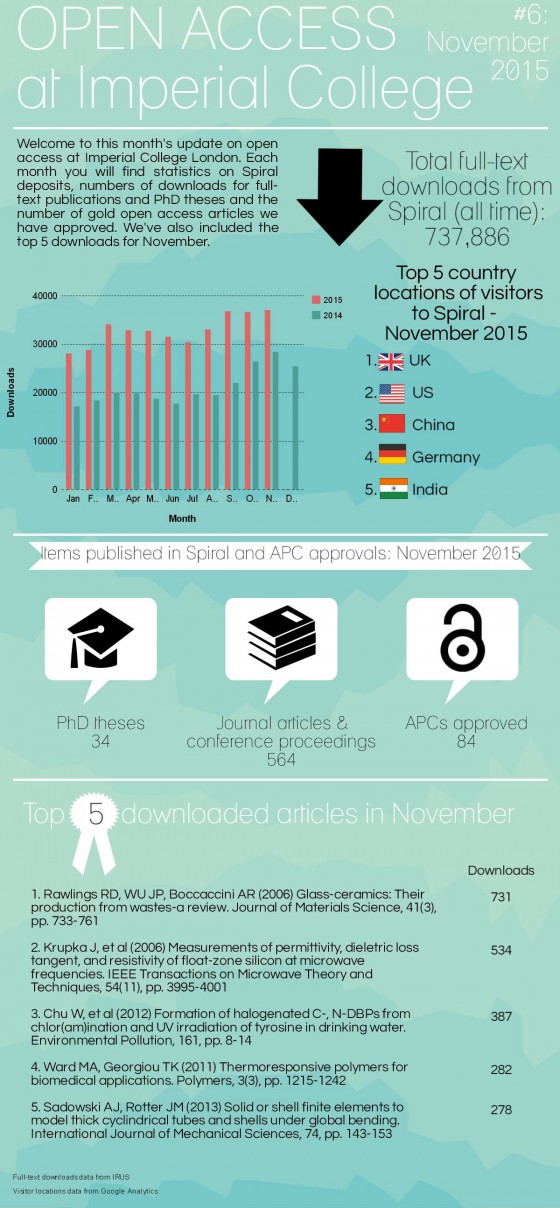
Open access in numbers – March 2016
How to implement ORCID at a university?
Last week I presented on Imperial’s ORCID implementation at the German Library Congress in Leipzig, as part of a panel on researcher identifiers. The College implemented ORCID in 2014 when it generated identifiers for academic and research staff; see my ORCID article in Insights for details. We use Symplectic Elements, our Current Research Information System (CRIS), to track ORCID iDs and to allow new staff to register – a straightforward process.
However, not all universities have a CRIS and some do not even have an institutional repository (repository systems like DSpace often support ORCID). This has triggered the question, in Leipzig but also in discussions with colleagues in the UK and elsewhere, on how a university should implement ORCID if they do not have a system (or systems budget) for ORCID. Some universities are also not (yet) in a position to become institutional members of ORCID, so they could not integrate with ORCID even if their local systems supported it.
How should a university ‘implement’ ORCID if it has no suitable systems, no or not much of a budget and if it may not be able to become an institutional ORCID member in the immediate future?
This sounds daunting but there is actually a simple, straightforward solution. ORCID is only effective if researchers use their iD – at minimum they should share it with their publisher so the iD can be added to the metadata of their research outputs. Universities can simply encourage staff to self-register – it is free for individuals and only takes a minute. Neither systems support nor ORCID institutional membership are required. Whether to register with ORCID remains the choice of the individual academic, which also gets around lengthy institutional processes for defining policy and evaluating the legal background.
Simply set up a page describing the advantages of ORCID – see Imperial’s ORCID pages as an example-, and start highlighting ORCID as part of the academic engagement that libraries undertake anyway. If and when the university eventually becomes a member of ORCID and makes systems support available you can simply ask researchers to link their existing iD. At that point there may already be some outputs with ORCID in the metadata!
Speaking of systems: I would suggest to add ORCID to a system that gives researchers direct benefit, and to only add it to systems if and when there is a clear business need. For example: if you do not plan to report on ORCID through the HR system, then why implement ORCID there right now?
The key for success with ORCID is to ensure academics understand and use ORCID.
P.S. As part of the support for the UK ORCID consortium, Jisc are currently working on a more detailed decision tree for ORCID implementation, and we are discussing future events to support ORCID uptake.
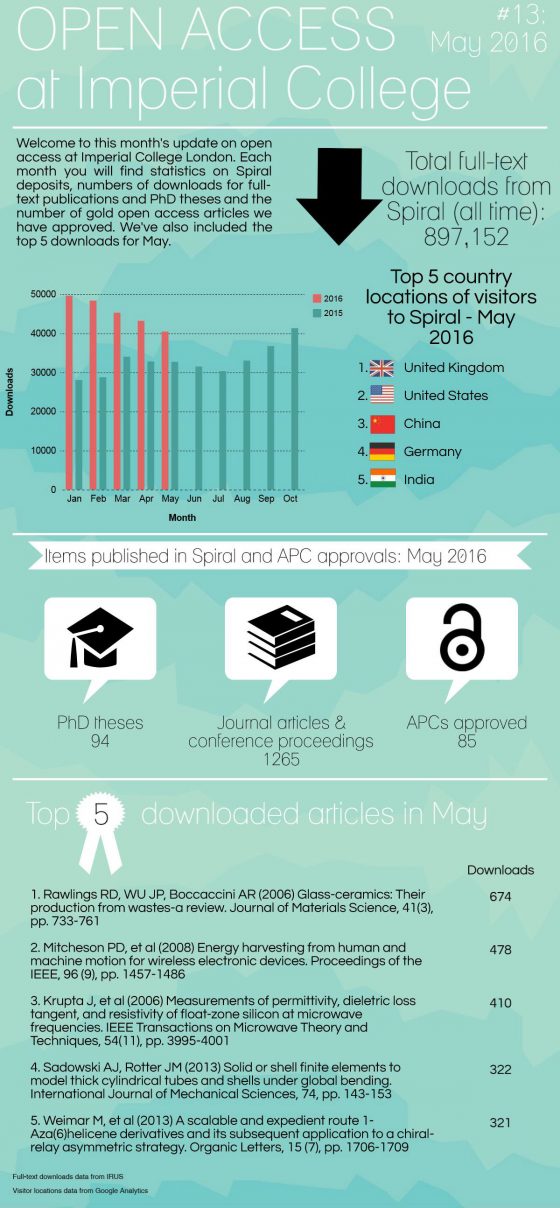
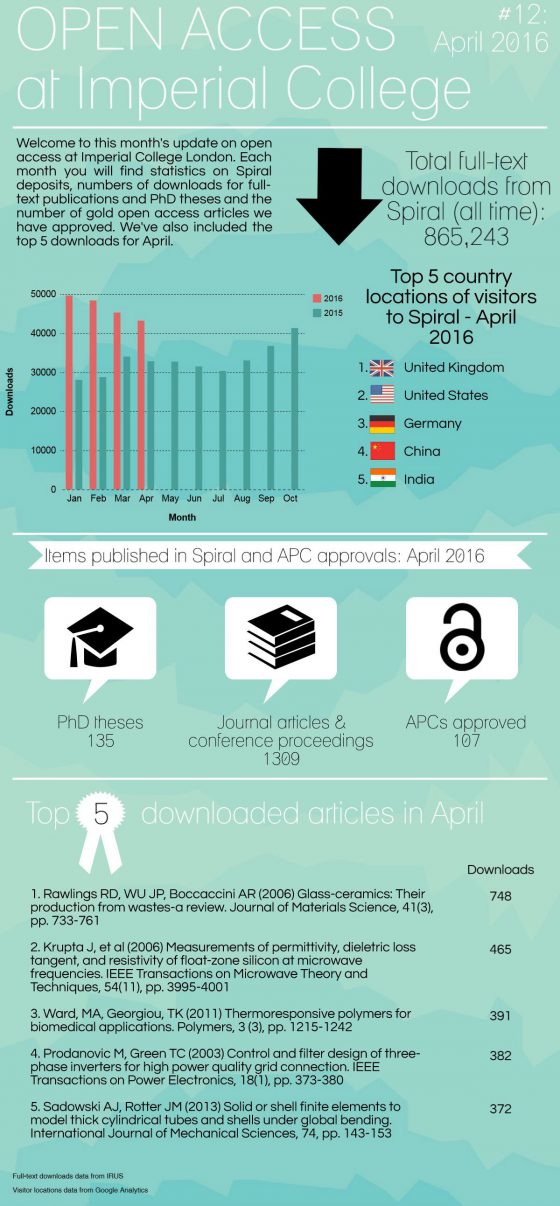
Open access in numbers – January & February 2016
How compliant are we with HEFCE’s REF open access policy? (Why Open Access reporting is difficult, part 2)
In what is hopefully not going to become a long series I am today dealing with the joys of compliance reporting in the context of HEFCE’s Policy for open access in the post-2014 Research Excellence Framework (REF). The policy requires that conference papers and journal articles that will be submitted to the next REF – a research assessment through which funding is allocated to UK universities – have to be deposited in a repository within three months of acceptance for publication. Outputs that are published as open access (“gold OA”) are also eligible, and during the first year of the policy the deposit deadline has been extended to three months of publication. The policy comes in force on 1st April and considering the importance of the REF the UK higher education sector is now pondering the question: how compliant are we?
As far as Imperial College is concerned, I can give two answers: ‘100%’ and ‘we don’t know’.
‘100%’ is the correct answer as until 1 April all College outputs remain eligible for the next REF. While correct, the answer is not very helpful when trying to assess the risks of non-compliance and for understanding where to focus communications activities. Therefore we have recently gone through a number crunching exercise to work out how compliant we would be if the policy had been in force since May last year. In May 2015 we made a new workflow available to academics, allowing them to deposit outputs ‘on acceptance’. The same workflow allows academics to apply for article processing charges for open access, should they wish to.
You would imagine that with ten months of data we would be able to give an answer to the question for ‘trial’ compliance, but we cannot, at least not reliably. In order to assess compliance we need to know the type of output, date of acceptance (to work out if the output falls under the policy), the date of deposit and the date of publication (to calculate if the output was deposited within three months). Additionally it would help to know whether the output has been made open access through the publisher (gold/immediate open access).
Below are eight issues that prevent us from calculating compliance:
- Publisher data feeds do not provide the date of acceptance
Publishers do not usually include the date of acceptance in their data feeds, therefore we have to rely on authors manually entering the correct date on deposit. Corresponding authors would usually be alerted to acceptance, but co-authors will not always find out about acceptance, or there may be a substantial delay. - Deposit systems do not always require date of acceptance
The issue above is made worse by not all deposit systems requiring academics to enter the date of acceptance. In Symplectic Elements, the system used by Imperial, the date is mandatory only in the ‘on acceptance’ workflow; when authors deposit an output that is already registered in the system as published there is currently no requirement to add the date – resulting in the output listed as non-compliant even if it was deposited in time. Some subject repositories do not even include fields for date of acceptance. - Difficulties with establishing the status of conference proceedings
Policy requirements only apply to conference proceedings with an ISSN. Because of the complexities with the publishing of conference proceedings we often cannot establish whether an output falls under the policy, or at least there is a delay (and possible additional manual effort). - Delays in receiving the date of publication
It takes a while for publication metadata to make it from publishers’ into institutional systems. During this time (weeks, sometimes months) outputs cannot be classed as compliant. - Publisher data feeds do not always provide the date of publication
This may come as a surprise to some, but a significant amount of metadata records do not state the full date of publication. The year is usually included, but metadata records for 18% of 2015 College outputs did not specify year or month. This percentage will be much higher for other universities as the STEM journals (in which most College outputs are published) tend to have better metadata than arts, humanities and social sciences journals. - Publisher data feeds usually do not provide the ‘first online’ date
Technically, even where a full publication date is provided the information may not be sufficient to establish compliance. To get around the problem that publishers define publication dates differently, HEFCE’s policy states that outputs have to be deposited within three months of when the output was first published online. This information is not usually included in our data feeds. - Publisher data feeds do not usually provide licence information
Last year, Library Services at Imperial College processed some 1,000 article processing charges (APCs) for open access. We know that these outputs would meet the policy requirements. However, when the corresponding author is not based at Imperial College – last year around 55% of papers had external co-authors – we have no record on whether they requested that the output be made open access by a publisher. For full open access journals we can work this out by cross-referencing the Directory of Open Access Journals. However, for ‘hybrid’ journals (where open access is an (often expensive) option) we cannot track this as publisher metadata does not usually include licence information. - We cannot reliably track deposits in external repositories
Considering the effort universities across the UK in particular have put into raising awareness of open access there is a chance that outputs co-authored with academics in other institutions have been deposited in their institutional repository. Sadly, we cannot reliably track this due to issues with the metadata. If all authors and repositories used the ORCID identifier it would be easier, but even then institutional repositories would have to track the ORCID iD of all authors involved in a paper, not just those based at their university. If we had DOIs for all outputs in the repositories it would be much easier to identify external deposits.
Considering the issues above, reliably establishing ‘compliance’ is at this stage a largely manual effort that would take too much staff time for an institution that annually publishes some 10,000 articles and conference proceedings – certainly while the policy is not yet in force. Even come April I would rate such an activity as perhaps not the best use of public money. Arguably, publisher metadata should include at least the (correct) date of publication and also the licence, although I cannot see a reason not to include the date of acceptance. If we had that, reporting would be much easier. If we had DOIs for all outputs (delivered close to acceptance) it would be even easier as we could track deposits in external repositories reliably.
Therefore I call on all publishers: if you want to help your authors to meet funder requirements, improve your metadata. This should be in everyone’s interest.
Colleagues at Jisc have put together a document to help publishers understand and implement these and other requirements: http://scholarlycommunications.jiscinvolve.org/wp/2015/03/26/how-publishers-might-help-universities-implement-oa/
What we can report on with confidence is the number of deposits (excluding theses) to our repository Spiral during 2015: 5,511. Please note: 2015 is the year of deposit, not necessarily year of publication.
Less is more? A metadata schema for discovery of research data
In recent years, universities have become more interested in the data researchers produce. This is partly driven by funder mandates, in the UK in particular the EPSRC Expectations, but also by a concern about research integrity as well as an increasing awareness of the value of research data. As a result, universities are building (or procuring) data repositories and catalogues – and these require metadata.
The world is not short of metadata schemas, and yet there is no widely used standard for how research data should be catalogued (not to replace disciplinary schemes, but simply to enable universities to track their assets and others to discover potentially valuable resources). In my keynote at RDMF14 I questioned whether universities building their own data infrastructures is always the most efficient way to address research data challenges, and I suggested that as a minimum we should aim for an agreement on a simple metadata schema for research data. This would save universities the trouble of having to come up with their own metadata fields, and perhaps, more importantly, such a consensus should help us in discussions with platform vendors and other data repositories. Academics are already using a wide range of disciplinary resources as well as generic repositories, and if we want to be able to harvest, search and exchange data we need a core metadata schema. This would also reduce the burden on academics to have to re-enter metadata manually.
One of the colleagues interested in this idea was Marta Teperek from Cambridge. After RDMF we exchanged the metadata fields currently used for research data at Imperial and Cambridge, with the idea to start a wider discussion. Today Marta and myself attended the kick-off meeting of Jisc’s Research Data Shared Service Pilot where we learned that Jisc are working on a schema for metadata – and there is considerable overlap, also with other initiatives. It seems the time is ripe for a wider discussion, and perhaps even for a consensus on a what could be the minimalist core of metadata fields or research data. Minimalist, to make it easy for researchers to engage; core, to allow institutions to extend it to meet their specific requirements.
To facilitate that discussion, I am going to propose a Birds of a Feather session at next week’s International Digital Curation Conference on this topic. As a starting point I have put together a suggestion, inspired by the fields used in the data catalogues at Imperial and Cambridge:
• Title
• Author/contributor name(s)
• Author/contributor ORCID iD(s)
• Abstract
• Keywords
• Licence (e.g. CC BY)
• Identifier (ideally DOI)
• Publication date
• Version
• Institution(s) (of the authors/contributors)
• Funder(s) (ideally with grant references; can also be “none/not externally funded”)
I would be interested to hear your thoughts – in person at IDCC or another event, or in the comments below. I will update this post with feedback from IDCC.
Update, 23/03/2016: Having discussed this with colleagues at IDCC I thought it useful to clarify something. As I mentioned above there are already several metadata schemas out there, and as you will see from the fields I have proposed above this is not about introducing something new. The issue that we face is that systems either don’t include such fields or they are not mandatory. I would like to explore if we can find a consensus on what is considered the mandatory minimum for discovery and funder compliance (including reporting). For example, institutions need to know who funded an output, but a widely used schema designed for a different purpose may list funder as optional. So in that sense this is not about a new schema as such, but about agreeing what has to be implemented as mandatory in order for us to link systems, reduce duplication etc. That could result in a new schema, but doesn’t have to.
Update, 26/03/2016: Back from IDCC; we had an interesting and wide-ranging discussion. Perhaps not surprisingly, we spent most of the time agreeing on definitions and understanding the use case. Most of the participants of the session were not from the UK and therefore not familiar with UK funder requirements.UK institutions are essentially looking for a pragmatic solution that helps us track datasets, report and meet funder requirements for discoverability. Introducing the concept of discoverability may not have been helpful for the international discussion as it made the proposal sound bigger than it is. We have no plans to replace or supersede disciplinary schemas (where these exist); the aim simply is to be able to point to disciplinary or other external repositories so that someone looking at data from an institutional system can learn that there is a dataset, what it may be about and where to locate it – and, ideally, further information such as detailed disciplinary metadata.
From the discussions with this international audience I am mostly drawing two conclusions: 1) This may be, at least partly, a UK-specific issue. 2) When engaging in discussions with metadata experts there is no such thing as a pragmatic definition – speaking about funder compliance and internal track of datasets for reporting is the more useful question.
For those interested in an example of a national consensus on metadata, look at Research Data Australia, provided by the Australian National Data Service.