Why are there probabilities in the forecast and why do they keep changing?
The UK Met Office has been making use of the remains of Hurricane Bertha to publicise the probabilistic aspects of their forecast. In particular, they have been publishing probabilities for various tracks of the storm across the UK.
Why is the forecast being made in terms of probabilities?
The classical idea of a forecast is a prediction of the precise value of something (e.g., temperature) at a particular point in space and time. This is referred to as a deterministic forecast. In a probabilistic forecast, this is expressed as a probability instead. For example, a forecast could say that there is a 60% chance that the temperature will fall between 21 and 25 degrees Celsius, a 20% chance that it will be below this range, and a 20% chance that it will be above.
The main reason for working with probabilities is that even with the huge amount of weather data available (satellites, weather stations etc.), forecasters are never completely certain about the current (and even past) state of the global weather system. This is partially due to the limits of accuracy of measurement devices, but mostly due to the fact that measurements cannot be taken at every single point in the atmosphere. This uncertainty is best expressed using probability, which can be used to quantify how certain forecasters are about the value of any meteorological quantity at any particular point around the globe. Having accepted that forecasters are uncertain about the current state of the weather system, it becomes clear that they would also be uncertainties about future predictions. It is the job of forecasters to make the best use of models and the continuous stream of observational data to minimise this uncertainty so that they can make as precise a forecast as possible.
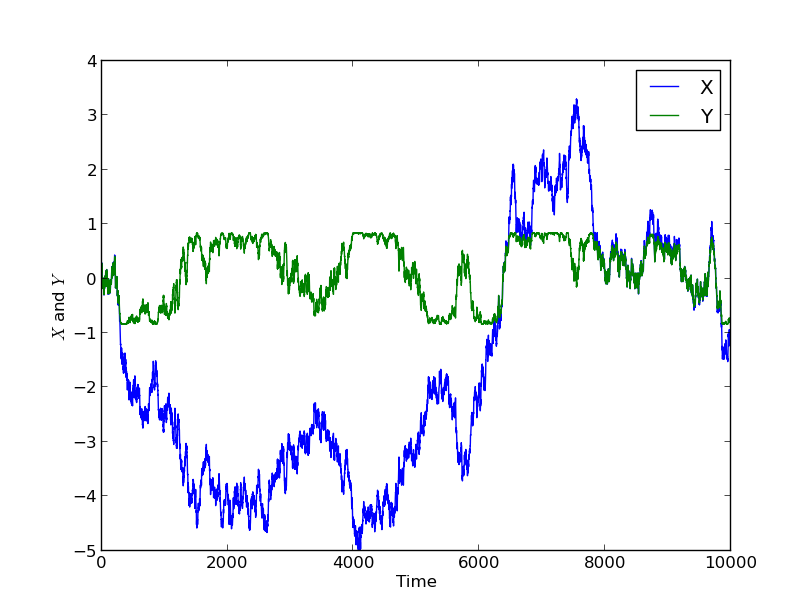
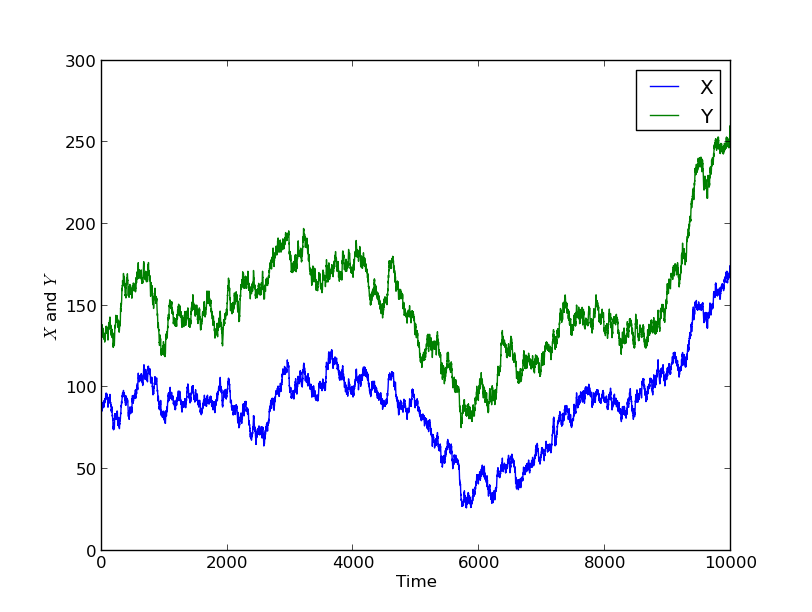
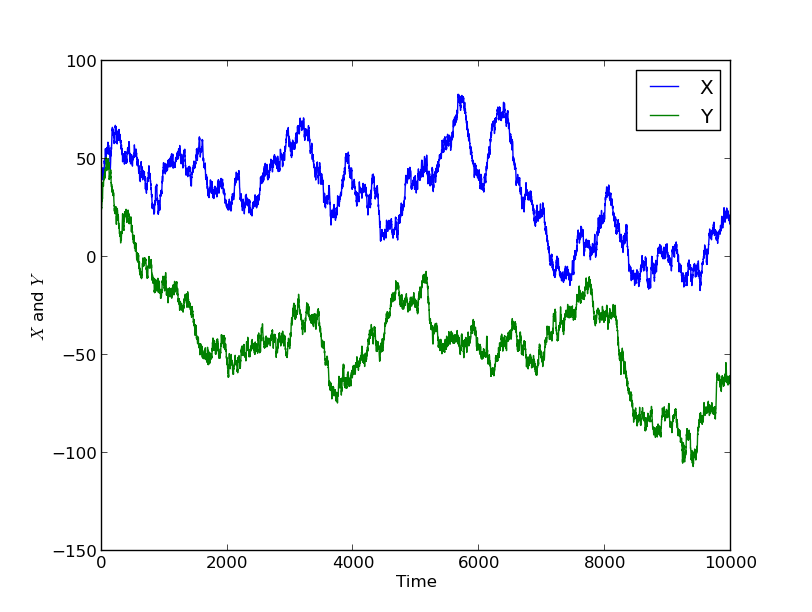
One of the features of forecasting a dynamical system such as the weather is that if we are initially uncertain about the system state, the uncertainty in the forecast tends to get larger as we try to make forecasts further into the future. If the system is chaotic (as the weather system is largely accepted to be) then eventually the level of uncertainty grows exponentially. This growth in uncertainty makes it harder and harder to predict the weather further and further into the future; this is why the Met Office only issues specific forecasts up to around 5 days ahead to the general public.
This problem is compounded by what is known as model error, i.e., errors due to the fact that the model is not a perfect model of reality. In weather models, these errors are mostly due to the multiscale nature of the atmospheric system which has features from thousands of kilometres in scale (planetary Rossby waves) down to microscopic details of turbulence in clouds, for example. These features on different scales all interact, and precise knowledge of them is required in order to produce a perfect forecast. In weather models, the atmosphere is divided up into cells, and features which are below the size of the cell cannot be represented directly. The total number of cells is limited by the requirement to run a forecast on a supercomputer quickly enough for it to be useful, and whilst the number of cells increases as computer technology progresses, there will always be a limit to how small they can be. Instead, the impact of features below the cell size on the weather must be included through “physics parameterisations”, which often work really well, but not in all situations, and are an important ongoing topic of research.
How are probabilistic forecasts made?
To make probabilistic forecasts, the forecasters’ uncertainty in the current state of the atmosphere is represented as an ensemble. This means that instead of storing a single representation of the atmospheric state detailing the wind speed, direction, pressure, temperature, and moisture values in each cell, the forecast is made using a collection, or ensemble, of several alternate representations of the atmospheric state. In regions where atmospheric quantities are known to a good degree of certainty, the ensembles have very similar values. The average over all the ensembles of this value represents the “best guess”, whilst the average distance from this value, i.e. the variance, over all the ensembles gives a quantification of the uncertainty in this value. In other regions where the quantities are less well known, over the oceans for example, the values that the ensemble members take are more spread out. To make the forecast, the weather model is run several times, once for each ensemble. This allows forecasters to compute similar means, variances, histograms and other statistics (such as the posible paths of a storm and their probabilities) for future times. Due to the increase in uncertainty over time that is characteristic of the weather system, these variances get larger and larger over time.
What is the use of a probabilistic forecast?
It seems frustrating to receive a probabilistic forecast rather than a deterministic one. However, probabilistic forecasts are extremely useful to policymakers, businesses and even the general public: they allow a quantification of risk. Rather than just saying that we don’t know which path a storm will take and how strong it will be, a probabilistic forecast provides an assessment of how likely various different scenarios are. For example, a deep low passing over the UK can cause storm surges, and it is important for the Environment Agency to be able to trade off the cost of evacuating an flood-prone area with the risk that a flood will occur. Probabilistic forecasts can also be used to help a business to minimise wastage (in managing stocks of ice cream, for example).
Why do the probabilities keep changing?
In the days leading up to the arrival of the low pressure zone formerly known as Hurricane Bertha, the Met Office issued several updates for probabilistic forecasts, each time showing a different set of probabilities for various tracks. It is easy to interpret this as the Met Office getting the forecast wrong, and then trying to correct it. However, what is actually happening is that the probabilities are being updated in the light of new observational data. The crucial point here is that the probabilities are relative probabilities which represent uncertainty in the forecast given all of the information that has been available so far. In the language of probability, these are called conditional probabilities. If there was different observational data (and past experience of the forecasters) available, then the probabilities would be different. And, when new observational data becomes available, the conditional probabilities must be updated to reflect this new information. There is a powerful mathematical formula for updating these probabilities known as Bayes’ Formula, named after Rev. Thomas Bayes, an 18th Century Presbyterian minister, who discovered it. To understand conditional probability, consider the following question: “What is the probability of rolling two fair 6-sided dice and getting a total score of 8?”. A bit of counting leads to the answer 5/36. However, if we receive a further piece of information, which is that the first die shows 2, then this value is updated to 1/6, which is the chance of getting a 6 on the other die. We see that the probability gets updated in the light of new information. In this example, the probabilities can be computed directly, but Bayes’ Formula becomes very powerful in more complex situations, such as forecasting the weather. So, when the Met Office update their probabilities, it does not mean that the previous probabilities were wrong, just that new information became available (in the form of new observational data from later times) and so new conditional probabilities must be computed. The mathematical process of blending new observational data with model simulations to update conditional probabilities is called data assimiliation. In the Met Office operational forecast cycle, new data is incorporated into the forecast every 6 hours.
[The book “Probabilistic Forecasting and Bayesian Data Assimilation: A Tutorial” by Sebastian Reich and Colin Cotter will shortly be published by Cambridge University Press.]